고정 헤더 영역
상세 컨텐츠
본문
■ BeautifulSoup 모듈
- 문자열 추출방식은 각 페이지마다 다르게 개발된 웹 페이지에 적용하기 어렵다.
- 홈페이지 내 데이터를 쉽게 추출할 수 있도록 도와주는 파이썬 외부 라이브러리
- DOM Tree형태로 구조화된 웹 페이지의 특정 요소를 이용하여 데이터를 추출하는 방법이 훨씬 유용
⇒ BeautifulSoup은 DOM Tree로 부터 데이터를 추출해 올 수 있는 다양한 기능을 제공
■ BeautifulSoup을 이용한 데이터 추출 및 파싱
- BeautifulSoup 모듈과 외장 파서 등이 설치되어 있어야 한다.
import requests
from bs4 import BeautifulSoup # BeautifulSoup 모듈 import
url = https://ko.wikipedia.org/wiki/%EC%9B%B9_%ED%81%AC%EB%A1%A4%EB%9F%AC # 위키피디아 “웹 크롤러 검색” URL
response = requests.get(url)
response.raise_for_status()
# requests 객체를 통해 얻어온 response.txt를 파서를 통해서 bs 객체로 변환 (내장파서 html.parser와 외장파서 lxml 등이 있다.)
soup = BeautifulSoup(response.text, 'html.parser')
# 이후, soup 객체가 제공하는 함수나 속성 등을 이용해 데이터 추출
■ Parser의 종류
| 종류 | 사용방법 | 특징 |
| html.parser | BeautifulSoup(markup, "html.parser") BeautifulSoup('<a></p>', 'html.parser’) -> <a></a> 형태로 강제 변경되어 처리됨 |
•파이썬이 제공하는 기본 파서
•괜찮은 속도
|
| lxml | BeautifulSoup(markup, "lxml") BeautifulSoup('<a></p>', 'lxml’) -> <html><body><a></a></body></html> 형태로 강제 변경되어 처리됨 |
•기본값
•아주 빠름
•외부 C 라이브러리 의존
|
| xml | BeautifulSoup(markup, "xml") BeautifulSoup('<a><b/>', 'xml') -> <?xml version="1.0" encoding="utf-8" ?> <a/> 형태로 강제 변경되어 처리됨 |
•아주 빠름
•XML 해석기 지원
|
| html5lib | BeautifulSoup(markup, “html5lib") BeautifulSoup('<a><b />', ‘html5lib') -> <html><head></head><body><a><b></b></a></body></html> |
•웹 브라우저와 동일한 방식으로 페이지를 분석하고 유효한 HTML5를 생성
•매우 느림
|
■ BeautifulSoup을 이용한 데이터의 접근순서와 데이터 검색 방법
1) BeautifulSoup 모듈 import
from bs4 import BeautifulSoup # BeautifulSoup 모듈 import2) 태그를 이용한 접근
soup.title # soup 객체에서 첫 번째로 만나는 title 태그 출력
soup.footer.ul.li # soup 객체에서 첫 번째로 만나는 footer 태그의 하위 태그 ul, 그리고 그 하위 태그인 li 태그 출력3) 태그와 속성을 이용한 접근
soup.a # soup 객체에서 첫 번째로 만나는 a element 출력
soup.a['id'] # a 태그의 속성들 중 “id" 속성값 정보 출력. 만약 속성이 존재하지 않을 경우 에러4) find()를 이용한 태그 내의 다양한 속성을 이용한 접근
soup.find("a", attrs={"title" : "구글봇"}) # a element의 속성 중 title 속성의 값이 “구글 봇”인 데이터 검색
soup.find(attrs={"title" : "구글봇"}) # title 속성이 “구글봇”인 어떤 element를 찾아 출력
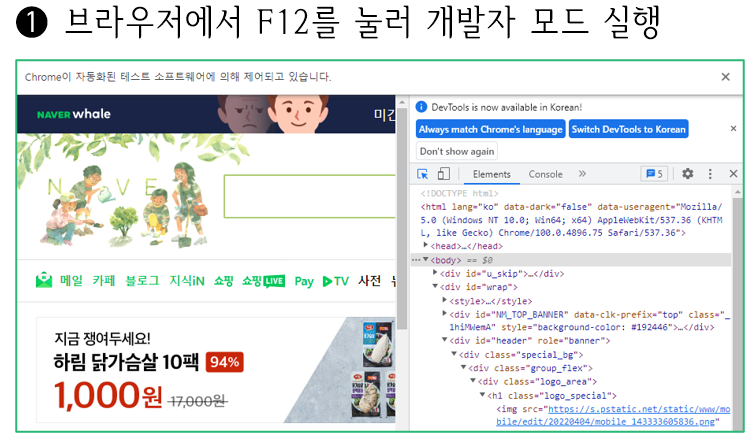
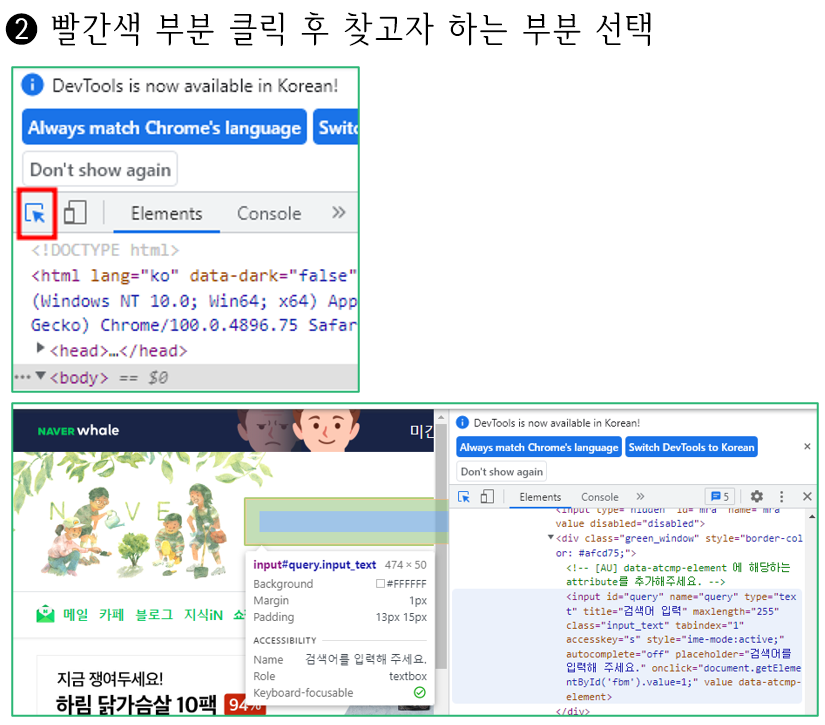
■ 웹 페이지 내에서 원하는 태그 찾기
- 웹 브라우저의 개발 툴 모드를 이용하여 원하는 데이터의 태그를 쉽게 검색할 수 있다.
■ 검색
- 태그: HTML의 해당 태그에 대한 첫 번째 정보를 가져옴
- 태그[‘속성’]: HTML 해당 태그의 속성에 대한 첫 번째 정보를 가져옴
import requests
from bs4 import BeautifulSoup
req = requests.get("https://www.naver.com")
html = req.text
soup = BeautifulSoup(html, "html.parser")
print(soup.title)
print(soup.title.name)
print(soup.title.string)| <title>NAVER</title> title NAVER |
# string이 있는 title 태그의 문자열 모두 검색
soup.title.find_all(string=True)
soup.title(string=True)
print(soup.img)
print(soup.img['src'])
print(soup.img['width'])| <img alt="" height="49" src="https://static-whale.pstatic.net/main/img_darkmode_v9@2x.png" style="padding-left: 90px" width="220"/> https://static-whale.pstatic.net/main/img_darkmode_v9@2x.png 220 |
{kind=link}
- find(): HTML의 해당 태그에 대한 첫 번째 정보를 가져옴
- find(속성=‘값’): HTML 해당 속성과 일치하는 값에 대한 첫 번째 정보를 가져옴
print(soup.find('a'))
print(soup.find(id='search'))| <a href="#newsstand"><span>뉴스스탠드 바로가기</span></a> <div class="search_area" data-clk-prefix="sch" id="search"> |
- find_all(): HTML의 해당 태그에 대한 모든 정보를 리스트 형식으로 가져옴
- limit 옵션으로 개수 지정 가능
print(soup.find_all('a', limit=2))| [<a href="#newsstand"><span>뉴스스탠드 바로가기</span></a>, <a href="#themecast"><span>주제별캐스트 바로가기</span></a>] |
- CSS 속성으로 필터링(class_로 클래스를 직접 사용 혹은 attrs에서 속성=값으로 필터링)
print(soup.find_all('span', class_='blind'))
print(soup.find_all('span', attrs={"class":"blind"}))| [<span class="blind">NAVER whale</span>, <span class="blind">네이버</span>,... ] |
- string으로 검색(해당 값이 있는지 없는지 검사할 때 활용, 정규 표현식과 함께 활용)
print(soup.find_all(string='자동완성 끄기'))| ['자동완성 끄기'] |
- select_one(), select(): CSS 선택자를 활용하여 원하는 정보를 가져옴(태그를 검색하는 find, find_all과 비슷함)
#태그 찾기
soup.select("title")
#특정 태그 아래에 있는 태그 찾기
soup.select("div a") #div 태그 아래에 있는 모든 a 태그 찾기
#특정 태그 바로 아래에 있는 태그 찾기
soup.select("head > title")
soup.select("head > #link1") #아이디로 태그 찾음
#CSS class로 태그 찾기
soup.select(".sister")
#ID값으로 태그 찾기
soup.select("#link1")
■ CSS 선택자
- CSS에서 선택자는 스타일을 지정하려는 요소를 선택하는 데 사용되는 패턴이다.
- 주요 CSS 선택자
| Selector | Example | Example Description |
| .class | .intro | class="intro“ 를 갖는 모든 요소 선택 |
| .class1.class2 | .name1.name2 | 클래스 속성 내에서 name1과 name2가 모두 설정된 모든 요소를 선택 |
| .class1 .class2 | .name1 .name2 | name1을 가진 요소의 하위 요소 중 name2를 가진 모든 요소를 선택 |
| #id | #firstname | id="firstname“ 를 갖는 요소 선택 |
| element | p | 모든 <p> 요소 선택 |
| element.class | p.intro | class="intro"를 갖는 모든 <p> 요소 선택 |
| element,element | div, p | 모든 <div> 요소와 모든 <p> 요소 선택 |
| element element | div p | <div> 요소 내의 모든 <p> 요소 선택 |
| element>element | div > p | 상위 요소가 <div> 요소인 모든 <p> 요소 선택 |
| [attribute=value] | [target="_blank"] | target="_blank“ 속성을 갖는 모든 요소 선택 |
| :nth-child(n) | p:nth-child(2) | 부모 요소의 두 번째 자식 요소에 해당하는 모든 <p> 요소 선택 |
■ 태그 내의 문장 가져오기
- get_text(): 검색 결과에서 태그를 제외한 텍스트만 출력
text = soup.find("span", attrs={"class":"blind"})
print(text)
print(text.get_text())| <span class="blind">NAVER whale</span> NAVER whale |
- get(‘속성’): 해당 속성의 값을 출력
text = soup.find("span", attrs={"class":"blind"})
print(text)
print(text.get('class'))| <span class="blind">NAVER whale</span> ['blind'] |
- string: 검색 결과에서 태그 안에 또 다른 태그가 없는 경우 해당 내용을 출력. 태그 안에 또 다른 태그가 있는 경우에는 None을 반환
text = soup.find("a", attrs={"data-clk":"squ.dust"})
print(text)
print(text.string)
result = text.find("strong", attrs={"class":"state state_normal"})
print(result.string)| <a class="air_area" data-clk="squ.dust" href="https://weather.naver.com/today/09680105"> <ul class="list_air"> <li class="air_item">미세<strong class="state state_normal">보통</strong></li> <li class="air_item">초미세<strong class="state state_bad">나쁨</strong></li> </ul> <span class="location">삼성동</span> </a> None 보통 |
- text: 검색 결과에서 하위 자식 태그의 텍스트까지 문자열로 반환
result = soup.find("a", attrs={"data-clk":"squ.dust"})
print(result)
print(result.text)| <a class="air_area" data-clk="squ.dust" href="https://weather.naver.com/today/09680105"> <ul class="list_air"> <li class="air_item">미세<strong class="state state_normal">보통</strong></li> <li class="air_item">초미세<strong class="state state_bad">나쁨</strong></li> </ul> <span class="location">삼성동</span> </a> 미세보통 초미세나쁨 삼성동 |
'Python 데이터 분석 > 웹 스크래핑' 카테고리의 다른 글
| 12. Selenium 모듈 (0) | 2023.11.01 |
|---|---|
| 10. 정규 표현식 - 3 (0) | 2023.10.30 |
| 09. 정규 표현식 - 2 (0) | 2023.10.27 |



댓글 영역