고정 헤더 영역
상세 컨텐츠
본문
1. 패키지 로딩
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences2. 데이터 로딩 및 확인
data = pd.read_csv('spam.csv', encoding='latin1')
print('전체 데이터 수 :',len(data))
data.head()3. 데이터 전처리
3.1 불필요한 컬럼 삭제
data.drop(['Unnamed: 2', 'Unnamed: 3', 'Unnamed: 4'], axis=1, inplace=True)3.2 'v1' 컬럼 라벨 인코딩
data['v1'] = data['v1'].replace(['ham','spam'],[0,1])data.head()
data['v1'].value_counts()3.3 결측치 확인
data.isna().sum()4. 학습/평가 데이터 분리
X_data = data['v2']
y_data = data['v1']
X_train, X_test, y_train, y_test = train_test_split(X_data, y_data, test_size=0.2, random_state=0, stratify=y_data)5. 텍스트 토큰 및 인코딩
| tf.keras.preprocessing.text.Tokenizer( num_words=None, filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n', lower=True, split=' ', char_level=False, oov_token=None, document_count=0, **kwargs ) |
| - num_words : 단어 빈도가 많은 순서로 num_words개의 단어를 보존한다. - filters : 걸러낼 문자 리스트를 적어준다. 디폴트는 '!"#$%&()*+,-./:;<=>?@[\]^_`{|}~\t\n' 이다. - lower : 입력받은 문자열을 소문자로 변환할지를 True, False로 적어준다. - split : 문자열을 적어 줘야 하고, 단어를 분리하는 기준을 적어준다. - char_level : True인 경우 모든 문자가 토큰으로 처리된다. - oov_token : 값이 지정된 경우, text_to_sequence 호출 과정에서 word_index에 추가되어 out-of-vocabulary words를 대체한다. |
tokenizer = Tokenizer()
tokenizer.fit_on_texts(X_train)
X_train_encoded = tokenizer.texts_to_sequences(X_train)
print(X_train_encoded[:5])
tokenizer.word_index5.1 텍스트 데이터 패딩
print('메일의 최대 길이 : %d' % max(len(sample) for sample in X_train_encoded))
print('메일의 평균 길이 : %f' % (sum(map(len, X_train_encoded))/len(X_train_encoded)))
plt.hist([len(sample) for sample in X_train_encoded], bins=50)
plt.xlabel('length of samples')
plt.ylabel('number of samples')
plt.show()max_len = 162
X_train_padded = pad_sequences(X_train_encoded, maxlen = max_len)
print("훈련 데이터의 크기(shape):", X_train_padded.shape)6. 모델 생성
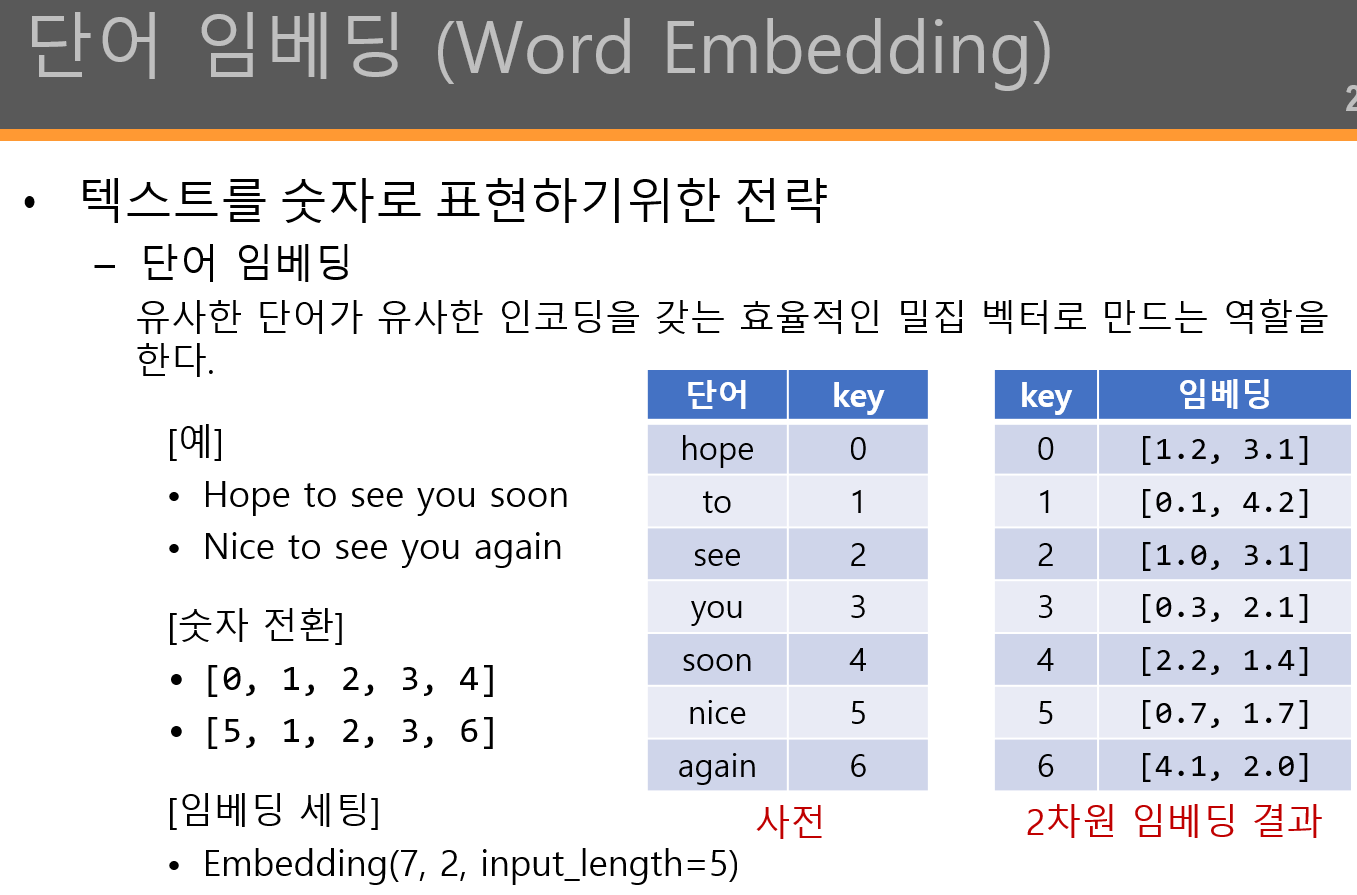
| [단어 임베딩] tf.keras.layers.Embedding( input_dim, output_dim, embeddings_initializer='uniform', embeddings_regularizer=None, activity_regularizer=None, embeddings_constraint=None, mask_zero=False, input_length=None, sparse=False, **kwargs ) |
| - input_dim: 단어 집합의 크기. 즉, 총 단어의 개수 - output_dim: 임베딩 벡터의 출력 차원. 결과로서 나오는 임베딩 벡터의 크기 - embeddings_initializer: 행렬 의 초기화 프로그램 - embeddings_regularizer: 행렬 에 적용된 정규화 함수 - input_length: 입력 시퀀스의 길이 |
from tensorflow.keras.layers import SimpleRNN, Embedding, Dense
from tensorflow.keras.models import Sequential
vocab_size = len(tokenizer.word_index)# + 1
embedding_dim = 32
hidden_units = 32
model = Sequential()
model.add(Embedding(vocab_size, embedding_dim))
model.add(SimpleRNN(hidden_units))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
history = model.fit(X_train_padded, y_train, epochs=4, batch_size=64, validation_split=0.2)7. 모델 평가
X_test_encoded = tokenizer.texts_to_sequences(X_test)
X_test_padded = pad_sequences(X_test_encoded, maxlen = max_len)
# evaluate: 테스트 모드에서 모델의 손실 값 및 측정항목 값을 반환
print("테스트 정확도: %.4f" % (model.evaluate(X_test_padded, y_test)[1]))8. 학습 곡선 시각화
epochs = range(1, len(history.history['acc']) + 1)
plt.plot(epochs, history.history['loss'])
plt.plot(epochs, history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'val'], loc='upper left')
plt.show()'데이터 분석 > 웹 스크래핑' 카테고리의 다른 글
| 05. LSTM을 이용한 기온 예측 (다변량 시계열 데이터 예측) (1) | 2023.12.26 |
|---|---|
| 04. LSTM을 이용한 항공기 탑승객 수요 예측 (1) | 2023.12.21 |
| 03. LSTM(Long Short-Term Memory) (0) | 2023.12.21 |



댓글 영역